2021. 7. 30. 22:15ㆍIT Study/Ai
오늘은 드디어 언어모델에서 가장 중요하다면 할 수있는 LSTM을 설명하는 날이다.
현재 많은 언어모델에서 채용 되고 있으며 성능또한 우수한 기술이니 이 챕터를 시작하는 날만 손꼽아 기다렸다.
LSTM의 내부구조는 그렇게 간단한 내용이 아니라 이 기술을 일반 텐서플로 책이나 간단하게 인터넷에서 모델설명만 본사람들은 당연히 블랙박스에 빠질 수 밖에 없다. 그렇기에 LSTM은 꼭 그 내부구조를 완벽하게 파악하는 것은 앞으로도 나 자신의 강력한 무기가 될 것이라고 생각한다.
RNN의 한계
LSTM의 기술을 모르기 전까지 우리는 RNN을 사용해서 언어모델을 구축했었다.
하지만 RNN은 엄청나게 큰 문제가 한가지 존재한다. 바로 기울기 소실과 기울기 폭발의 문제다. 인공지능의 학습 과정은 기울기가 제일 큰 부분을 담당하기에 기울기에 문제가 있다면 학습이 원할하게 이루어지는 것은 어렵다고 볼 수있겠다.

위의 그래프는 RNN에서 h(prev)와 Wh의 Matmul식의 역전파를 1열로 나열해 놓은 모습이다. 잘 보면 앞에서 온 dh가 역전파를 거듭할 수록 Wh.T가 계속 곱해지는 것을 볼 수있다. (Wh.T는 한 뭉치안에서 모두 동일한 값이다.)
*Truncate BPTT한 뭉치 역전파는 update가 중간에 이루어지지않고 한 뭉치가 끝난후 한꺼번에 update된다.
-상당히 당연한 소린데 왜나하면 각각의 시각에서 순전파를 진행할 때는 Wh를 기준으로 진행 한 것이기 때문에 하나 하나 역전파를 진행할 때 Wh를 update를 한뒤 뒤 시각 역전파를 진행하면 로직이 모순되기 때문이다.
여기서 좀더 쉽게 기울기 소실과 폭발을 이해하려면 Wh.T가 스칼라값이라고 가정하면 편하다. 만약 Wh.T가 0.1이라고 하자 그러면 당연히 역전파가 진행 될 수록 기울기는 0으로 수렴하는 값이 되어 버릴 것이다. 반대로 1.0이넘어가면 무한대로 발산하게 될 것이다.
하지만 Wh.T 스칼라값이 아니라 행렬이다. 그래서 이 경우에는 "특잇값"이라는 개념을 사용한다. 특잇값이란 데이터가 얼마나 퍼져있지를 나타내는데 여기서 특잇값의 최댓값이 1이 넘어가면 기울기 폭발이 일어날 가능성이높고 1보다 작으면 기울기 소실이 일어날 가능성이 높다.
기울기 클리핑
기울기 클리핑이란 앞서 얘기한 RNN의 기울기 폭발에대한 대처법이다.
이 기울기 클리핑은 정말 단순한 알고리즘을 가지고 있는데 바로 문턱값이라는 수를 사용하는 것이다.
여기서 g는 우리가 사용하는 기울기의 총합이고 threshold는 설정해줄 문턱값이다. g의 L2노름이 문턱값보다 커지면 g를 강제적으로 줄어들게 하는 로직이다.
이 기술은 간단하면서 상당히 효과적이라고 알려져 있는데 실제로 LSTM에서도 사용되는 것을 볼 수있다.
LSTM
이제 드디어 LSTM을 설명할 시간이다. 하지만 글순서를 보면 분명히 기울기 소실에 써야하는거아닌가? 라고 말할 수 있는데 왜 LSTM이 나왔냐면 기울기 소실을 해결하는 기술이 LSTM이기 때문이다.
LSTM이 기존 RNN과의 차이점은 몇개 없지만 상당히 명확하게 말할 수있다. 바로 "게이트"의 유무와 기억셀이다.
게이트란 입력의 세기를 조절해주는 장치라고 말할 수 있겠다. 예를들어 10의 값이 0.1의 세기를 가지고있는 게이트를 지나면 1의값이 출력이 되는 것이다.
LSTM에서는 이 게이트를 이용해 기억셀을 망각하게 할 수도있고 새로 기억하게 할 수있으며 새로 기억되는 정도를 만질 수 있으며 앞으로 전달해줄 은닉상태가 얼마나 중요한지의 정도를 설정해 줄 수 있다.
앞에서 기억셀이라는 이야기가 나왔다. 이 기억셀은 RNN에서 나타내는 은닉상태하고는 좀 다른 성격을 띄고있다. 이 기억셀은 c(t)라고 표현하며 따로 출력을 하지않는다. 즉 외부로 나가지않고 오직 LSTM내부에서도는 값이다. 이 c(t)이 대부분의 기억능력을 담당한다.
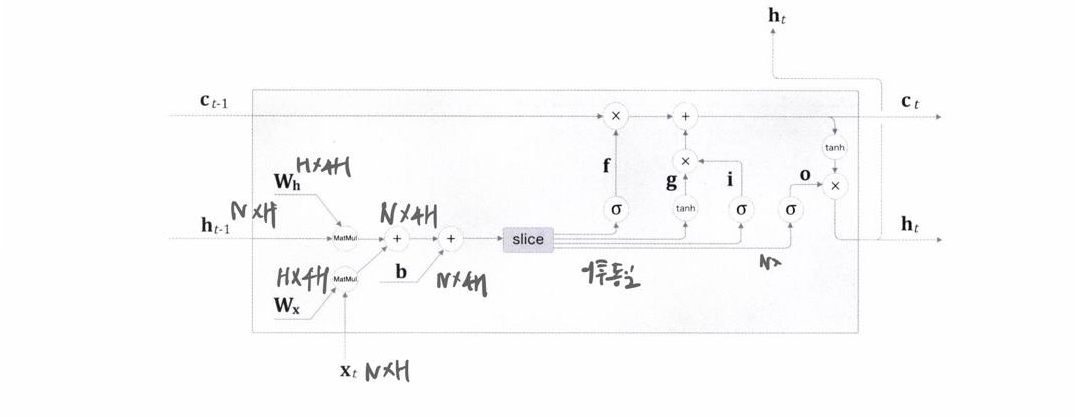
위 사진이 LSTM의 내부사진이다. 이 모습을 처음 보는 사람이라면 상당히 눈이 어질어질 할 수도 있겠다. 물론 필자도 처음 볼 때는 당황을 감추지 못했다.
일단 먼저 설명할 부분은 h(t-1)하고 x(t)의 연산인데 이 두개는 시그마(sigmoid)3개와 tanh 연산으로 모두 이어져있는 것을 볼 수있다. 여기서 생략된 연산이 있는데 이 4개의 노드들은 모두 각자의 가중치2개와 바이어스1개가 존재한다.
위의 식에서 i는 f,g,i,o로 바뀔 수있다. 그렇다면 f,g,i,o 이 4개가 대체 무엇을 나타내는 것인가가 중요할 것이다. 먼저 말하자면 이 4개의 기호가 앞에서 말한 게이트이다. 정확히는 3개가 게이트라고 할 수있겠다.(g제외)
먼저 f이다. 이 게이트는 forget 게이트라고 말하며 한국어로는 망각게이트이다.
먼저 우리는 sigmoid의 특성을 짚고 넘어가야하는데 익히 알고 있듯이 sigmoid함수는 0~1사이 값을 나타낸다.
우리가 게이트를 설명할 때 게이트란 입력값의 세기를 결정해주는 장치라고 했다. 즉 인풋값이 sigmoid를 지나면 0~1사이로 변환이되고 그 값이 c(t-1)에 곱해져 기억셀값의 세기가 결정되는 것이다.
망각게이트의 특성답게 기억셀에 0~1사이의 값이 곱해지게 된다면 어떤값은 별 영향없이 통과하는 반면 어떤 값은 0근처값이 곱해져 기억셀에서 삭제가 될 것이다. 그 값은 물론 학습이 진행되면서 중요하지 않은 기억일 것이다.
다음엔 g이다. 위 i에대한 식에서 i값들을 g로 모든 바꾼 것이 g게이트의 식이 된다.
g 게이트는 추가 게이트라고 할 수있다. 학습을 진행하면 망각뿐만아니라 기억셀에 기억해줘야 할 내용을 추가하는 로직도 필요할 것이다. 이 로직은 상당히 단순한데 기본적으로 tanh연산까지는 우리가 지금까지한 RNN연산의 출력값 하고 완벽하게 일치하기 때문이다. 그렇다면 이 출력값은 당연히 정보 자체일 것이다.
이 정보를 단순하게 추가 즉 "덧셈"연산을 통해 연산해주면 기억셀에 정보를 추가할 수 있게되는 것이다.
다음엔 i이다. 이 i는 g하고 상당히 관련이 깊은데 이 게이트의 역할은 정보의 분별 수용과 관련이 있기 때문이다.
이 게이트역시 sigmoid를 지나면 0~1사이의 값이 된다. 그말인 즉슨 세기의 조정이 들어가는 것이다. 그러면 무슨 값의 세기가 조정이 되냐, 그 것은 추가될 정보의 세기인 것이다. g 연산 중간에서 불필요한 정보는 날리고 필요한 정보만 추가하도록 조정해주는 것이 i의 역할인 것이다.
마지막으로 o 게이트이다. 이 LSTM은 RNN의 로직을 기반으로 만들어진 모델이다. 그렇기에 은닉계층의 상태는 아무리 기억셀이 있더라고 거의 모든연산에 사용될만큼 엄청난 중요성을 가지고 있다. 그렇기에 o게이트는 이 은닉계층의 상태를 조정해 다음계층에 흘려주는 역할을 한다.
하지만 이 게이트의 마지막 과정은 좀 특이한데 기억셀의 값과 o게이트의 값을 x해줘서 은닉상태를 흘려주는 것을 확인할 수있다.
기억셀을 마지막에 x연산해주는 것은 너무나 당연하게 기억셀을 만들고 갱신하면 그 것을 "사용"해야 하기 때문이다. 무엇이든지 사용을 안하면 그 것을 만드는 필요조차 없는 것이 아닌가,,
하지만 이 x연산은 지금까지 한 합성곱연산이 아니다. 아다마르 곱이라하는 곱연산을 사용하는데 그 내용은 1:1 원소별 곱이다. 기호로는 ⊙라고 쓴다. 이 뿐만아니라 게이트 후 x연산들은 모두 아마다르 곱연산을 사용한다.(행렬의 형상 확인)
ht = o ⊙ tanh(ct)가 마지막 연산이 되겠다.
앞 내용으로 기억셀과 게이트에대해 충분히 이해 했으리라 생각한다. 그렇다면 이 구조가 어떻해 기울기 소실을 해결하게 되는 것인가? 그 것은 forget게이트와 +역전파, x역전파에서 답을 구할 수있다.
LSTM의 전체 로직이다. LSTM에서는 역전파를 할 때 ct인 기억셀이 가장 중요한 역할을 할 것이다. 역전파가 아무리 많이 이루어져도 가장 최근의 기억이 없어져서는 안되는 경우가 분명 존재할 것이기 때문이다. 그럼 ct위주로 역전파를 보면 기울기 소실 문제의 해결법이 이해가 될 것이다.
ct의 역전파는 단순하다. 어려운 연산이 없이 때문이다. 가장먼저보이는게 +노드와 x노드이다. 여기서 눈치가 빠른사람은 분기노드까지 보일 것이다.
일단 분기노드는 건너뛰고 +노드부터 보자.
+노드의 역전파는 같은값을 흘려주기였다. 즉 기울기가 변하지 않는다.
그러면 x노드를 보자 여기서 LSTM에서 가장 중요한 부분이 나온다. 곱셈노드의 역전파는 반대편의 값을 전치해서 곱해주는 것이였다. 그럼 c(t-1)의 역전파는 dct X f 일것이다. f값은 시그모이드의 성질로인해 0~1사이의 값이다.
그러면 여기서 의문점이 하나 생길 것이다. dct에서 1보다 작은 값을 곱해주니 당연히 기울기가 점점 줄어드는 것이 아닌가? 반은맞고 반은 틀리다.
우리는 f가 forget게이트라는 것을 잊으면 안된다.
forget게이트에서 0에 가까우면 필요없는 정보 즉 뒷내용 해석에 앞내용이 필요없다는 뜻이였다. 반대로
forget게이트에서 1에 가까우면 중요한 정보 즉 뒷내용 해석에 앞내용이 매우 필요하다는 뜻이다.
그렇다면 f가 0에 가깝다는 말은 기울기 역전파에서 앞 쪽으로 값을 굳이 넘겨줄 필요가 없다는 말로 해석을 할 수있다.반대로 f가 1에 가깝다는 말은 기울기역전파가 꼭필요하다는 말이 될 수있다. 다시말해 구조상으로 기울기 소실이 일어날 가능성이 아주많이 줄어든다는 뜻이다. (기울기 소실이 일어날 가능성이 없다는게 아니라는 것은 충분히 이해했으리라 생각한다.)
하나 넘어간 분기노드의 덧셈연산 역시 기울기 소실방지에 조금이라도 한 몫을 할 것이라고 본인은 생각한다.
ps.f,g,i,o의 가중치 바이어스들은 한꺼번에 통합, 관리한다.( x[wf,wg,wo,wo] , h[wf,wg,wo,wo], b[wf,wg,wo,wo] )
LSTM 행렬의 형상
행렬의 형상의 이해는 모델의 응용력을 상당히 높여준다. 그렇기에 LSTM내부의 가중치와 바이어스, 입력, 출력 행렬의 형상도 짚고 넘어 가보자.
먼저 정의이다.
V = 단어의 종류 수
D = 인풋값 크기
N = 미니배치 수
H = 은닉노드 수
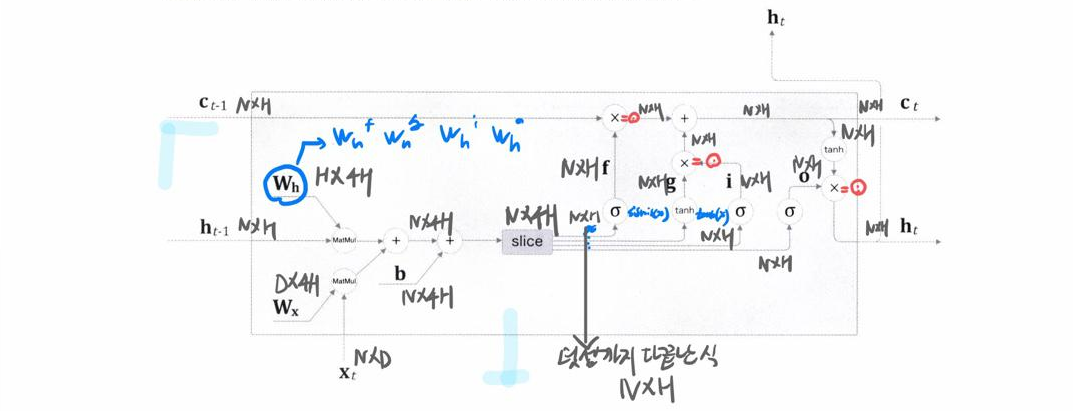
LSTM의 있는 모든 분기와 노드 출력의 행렬의 형상을 정리해 놓은 것이다. 다 설명은 하지않을 것이고 중요하다 생각되는 몇몇부분만 설명을 진행 하겠다. 앞서 RNN에서의 행렬의 형상을 잘 이해했다면 무리없이 도출할 수 있을 것이라 생각한다.
먼저 Wh부분이다. 앞서 말했듯이 게이트마다 가중치2개와 바이어스가 존재하는데 LSTM을 구현할 때는 모두 통합해서 관리하기 때문에 H * 4H가 된다.
다음은 slice부분이다. 통합관리한 가중치를 4개의 노드로 나누어 주기때문에 이 노드를 지나면 4H가 H로 변하게 된다. 여기서 부터는 시그모이드를 지나든 tanh를 지나든 모든 노드에 연산을 각각해주기 때문에 행렬의 형상이 변하지 않는다.
그러면 여기서 가장 중요한 부분 앞서 우리는 ht를 출력할 때 아마다르 곱연산을 한다고 설명했다. 이 곱은 1:1 원소대응 연산으로 행렬의 형상이 변하지 않으며 피연산대상의 형상은동일해야 한다. 그렇기에 쭉쭉 진행이 되면 기억셀의 형상 또한 N * H라고 특정할 수 있게 된다. 그러면 c(t-1)과 f의 곱연산은 과연 합성곱 연산일까 아마다르 연산일까 물론 아마다르 연산으로 진행되는 것이다. 이렇게 추론할 수도있고 단순히 forget게이트의 특성으로인해 각 노드에 1:1 대응연산 하는걸 생각해내도 아마다르 곱연산인 것을 도출 할 수 있게된다.
LSTMLM과 성능향상 기법
LSTMLM은 RNNLM과 크게 다르지 않다. 똑같이 Truncated BPTT를 사용하며 시계열데이터를 한번에 처리하기위해 TimeLSTM을 제작하고 똑같이 임베딩후 LSTM 후 Affine 후 SoftMaxwithLoss를 적용한다.
이렇게 모델이 완성되면 이제 성능을 향상하는 방법만 남았다. 그 방법중 가장 대표적인 것은 3가지 인데 하나는 그냥 여러겹 LSTM을 겹쳐주는 것이고 하나는 DropOut 나머지 하나는 가중치공유 기법이다.
먼저 LSTM을 겹쳐주는 것을 해보자. 사실 이 겹쳐준다는 것은 너무나도 간단한 아이디어 라서 설명할 거리가 있나? 라고 생각할 수있지만 여기서 주목해야할 점은 "행렬의 형상"이다. 결론부터 말하자면 가중치를 초기화할 때 1차LSTM 형상에서 변형을 조금해주면 된다.
1차 LSTM의 출력형상은 N * H라고 위에서 도출 완료했다. 그렇다면 2차 LSTM의 입력형상은 N * H가 될 것이다.
이 것을 토대로 모든 형상을 도출해보자.
이런식으로 Wx의 MatMul만 조정해주고 계산이 들어가게 되면 나머지 형상은 1차 LSTM형상과 동일한 것을 볼 수있다.
참고로 H와D를 그냥 같은 값으로 지정해주면 굳이 따로 설정 안해주고 같은 변수로 초기화해줘도 상관없다.
DropOut은 상당히 유명하고 또 대부분의 모델에서 자주 채용이 되고있는 기술이라 모르는 사람이 거의 없을 것이다.
이 DropOut은 모두가 익히 알고 있듯이 과적합을 피하는 방법으로 자주 사용이 된다. RNN,LSTM은 과적합이 다른 모델보다 자주 발생한다. 심지어 만약 위에 사용한 LSTM을 겹치는 기술을 사용할시 그 문제는 더욱 커지게 된다.
그렇다면 DropOut을 사용하는 것은 매우 좋은 아이디어 처럼보이는데 이 기술을 무턱대고 사용했다가는 오히려 학습이 나빠지는 경우가 생긴다. 그 경우는 시간축에 DropOut을 끼는 경우인데 RNN,LSTM의 모델의 특성을 생각해보면 순전파, 역전파시 시각이 진행됨에 따라 기억해야할 데이터를 다음 시각에 넘겨주는 과정을 거친다. 만약 그 과정에서 DropOut이 끼게된다면 넘어아야하는 중요한 정보가 사라질 수 있는 위험이 생기는 것이다.
해결책은 DropOut을 시간축이아닌 세로축(모델간)으로 추가를 해주는 것이다. 만약 LSTM을 두개 겹친다면 그 사이에 위치하는 것이다. 이 방법은 상당히 유용하다.
그럼 시간축 DropOut은 사용불가능한 기술인가하면 그 것은 또 아니다. 시간축 DropOut을 활용하는 기술은 현재까지도 여러 방법과 논의들이 오가고있으며 실제로 사용가능한 방법도 나왔다. 하지만 여기선 기술하지는 않겠다. 궁금하다면 "변형 드롭아웃"을 검색해 보길 바란다.
마지막 기술은 가중치 공유이다. 말그대로 다른 모델끼리 가중치를 공유하는 것이다. 모델끼리 같은 가중치를 공유하면 학습할 파라미터가 줄어드니 최적화 측면에도 좋고 과적합 측면에서도 좋은 결과를 보이니 1석2조인 셈이다.
여기선 특히 임베딩 가중치와 Affine가중치를 공유하는걸 추천하는데 그이유는 행렬의 형상에 있다.
계속 행렬의 형상을 강조하고있는데 이 가중치 공유는 행렬의 형상이 조건에 맞지않으면 불가능하기 때문이다. 그렇기에 응용측면에서 형상을 이해하는 것은 정말 중요하다.
다시 본론으로 넘어와서 임베딩의 가중치의 형상은 V * D이다. Affine의 가중치형상은H * V이다(전 포스팅 확인).
여기서 Affine의 가중치를 전치하면 V * H가 될 것이다. 그러면 V는 맞지만 D,H가 틀리게 된다. 하지만 우리는 학습을 진행 할때 D와 H를 설정해줄 수있다. 여기서 D와 H를 통일시켜주면 가중치 공유의 조건이 완료가 되는걸 논리적으로 도출해 낼 수가 있다.
실제로 가중치공유를 적용한 모델들은 D와 H를 통일시켜주는 모습을 볼 수 있다.
마무리
이렇게 최적화,성능향상 까지 마무리된 LSTM은 상당히 큰 데이터에도 적용이 가능한 것을 볼 수있을 것이다. 이번 포스팅에서 설명한 기술은 현재까지도 현업에서 자주 애용되고있는 기술들이며 자연어처리에서 빠질 수 없는 요소들이다. 그렇기에 지금까지 포스팅한 어떤 글보다도 섬세하고 정확하게 쓰는 것을 목표로 했다.
출처 : 밑바닥부터 시작하는 딥러닝2
'IT Study > Ai' 카테고리의 다른 글
| Seq2Seq 개선 (Reverse, Peeky, Attention-어텐션) (0) | 2021.08.14 |
|---|---|
| seq2seq(Sequence to Sequence) (0) | 2021.08.04 |
| RNNLM(RNN Language Model) (0) | 2021.07.28 |
| RNN, Truncated BPTT, Time RNN (0) | 2021.07.27 |
| 자연어처리 Word2Vec 개념 (0) | 2021.07.18 |